Po letech jsem se dokopal zase něco vytvořit. Může za to Jakub Rejnuš a Etalon link buildingu, kteří uspořádali první český SEO Bootcamp. A patří jim za to velké díky! Podmínkou vstupu na akci totiž byla přednáška od každého účastníka.
Jako téma jsem zvolil výstup z mojí práce u jednoho klienta se zaměřením na to, jak prioritizovat kombinace filtrů na eshopu. O co jde?
Jedním z klasických výstupů klasifikační analýzy klíčových slov (kterou popsal Marek Prokop na svém webu Vyhledavace.info už v roce 2012) je porovnání hledaností jednotlivých filtrů. Řekněme, že filtrem může být velikost, barva, značka, styl atp. Doposud jsem porovnával vždy jen tyto filtry mezi sebou.
Jenže na eshopech se filtry běžně kombinují. Vyberu si barvu a ještě velikost (např. červená trička xxl). Nebo značku a styl (např. sportovní trička Nike). Jak ale zjistím, které kombinace filtrů jsou ty nejzajímavější? Které lidi nejvíc hledají? Na to nám klasický výstup v podobě porovnání jednotlivých filtrů mezi sebou neodpoví.
Řešením je tedy porovnat jednotlivé kombinace filtrů mezi sebou. Z toho se dá následně vyčíst, že například kombinace velikosti a barvy má výrazně zajímavější hledanost než kombinace značky a stylu. A to dokonce na úrovni jednotlivých druhů zboží, pakliže je analýza klíčových slov zpracována nad širším sortimentem.
Poznámka: Na začátek pro jistotu ještě vysvětlím používané názvosloví. Filtr je pojmenování nějakého užšího výběru. Tedy např. barvy, velikosti atp. V rámci klasifikační analýzy klíčových slov jsme si zvykli používat spíše slovo segment. Hodnota segmentu pak je jeho určitá hodnota. Segmentem tak bude např. barva, velikost, značka, styl atp. Hodnotou segmentu pak např. červená, xxl, nike, atp.
Jak to vypadalo doposud?
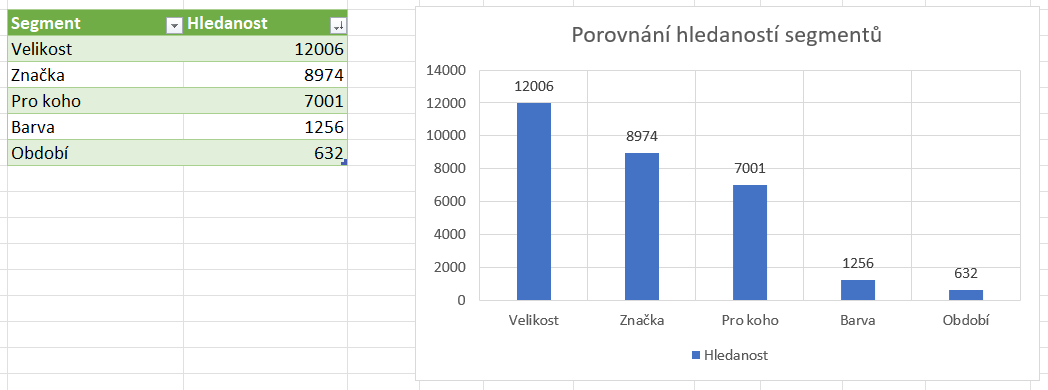
Z klasifikační analýzy klíčových slov vzešlo, že hledanost segmentu “Velikost” je nejzajímavější. Druhý je “Značka”, třetí “Pro koho” atd. Na tomto základě jsme se většinou začali prioritně zajímat o všechny kategorie s vybraným filtrem velikosti.
Co je na tom ale špatně?
Graf výše nám ukazuje pouze porovnání jednotlivých segmentů mezi sebou. Co když je ale kombinace segmentů “Značka” a “Pro koho” zajímavější, než samotný segment “Velikost”? A pro který typ zboží to vlastně platí?
Abychom se to dozvěděli, musíme vytvořit kombinace jednotlivých segmentů a ty následně porovnat mezi sebou. A to ideálně pro konkrétní typ zboží. Většinou se totiž v rámci analýzy klíčových slov zpracovává celý sortiment najednou. V našem modelovém příkladě se tedy najednou zpracovávají trička, mikiny, kalhoty, bundy atp. A logicky nebudou priority parametrů stejné pro každý jeden typ sortimentu.
Poznámka: Pro účely tohoto článku se budu zabývat jen porovnáním hledaností jednotlivých kombinací. Nebudu to komplikovat konkurenčností nebo byznysovou důležitostí. Pro ilustraci nám hledanost bude bohatě stačit.
Jak zjistíme kombinace segmentů a jejich hledanost?
Využijeme data z klasifikační analýzy klíčových slov. Výstupem z ní jsou data v excelu, kde každá jedna fráze je rozdělena do tzv. segmentů. Z každého jednoho segmentu se pak většinou na eshopu stane filtr.

Abychom se dostali k možnosti vytvořit kombinace parametrů, musíme data dostat zpět do Open Refine. V něm vytvoříme nový sloupec. Nad tímto sloupcem spustíme funkci (Edit columns / Join Columns). Pozor, funkce není dostupná ve verzi 3.0. Ve verzi 3.4.1 už ano.
Potřebujeme se dostat do stavu, kde budeme mít spojené jednotlivé hodnoty segmentů a ty budou odděleny pomlčkou.
Otevře se nám toto okno:

Ze všeho nejdříve je vhodné seřadit pořadí sloupců v levé části podle hledanosti jednotlivých segmentů. Využijeme k tomu klasický graf porovnání hledaností jednotlivých segmentů.
Na základě našeho ukázkového příkladu bychom tedy měli změnit pořadí v levé části okna na:
- Velikost
- Značka
- Pro koho
- Barva
- Období
Následně v pravé části vložíme oddělovník. Já používám “ – ”. A taky je vhodné zaškrtnout možnost “Skip nulls”. To zajistí, že se nám do výsledku promítnou pouze hodnoty těch sloupců, které nejsou prázdné.
Co se stane?
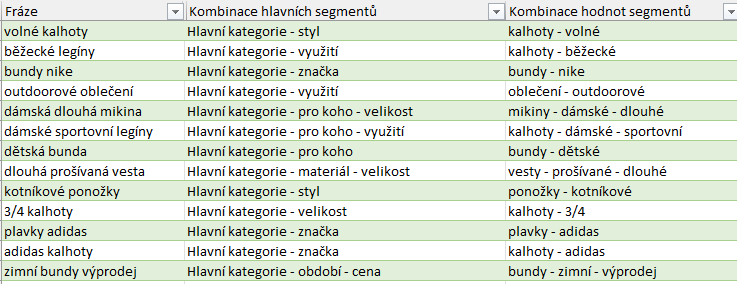
Pro každou jednu frázi se vezmou hodnoty všech segmentů a vypíší se za sebe, odděleny pomlčkou. Výsledkem po exportu do excelu je něco takového:

Když podobný postup použijeme i pro názvy sloupců, tedy názvy segmentů, vznikne něco podobného:
A když už máme otevřený Open Refine, tak ještě spočítáme, kolik segmentů má každá jedna fráze.
K tomu v Open Refine využijeme jednoduchou funkci: length(value.split(“ – „))
Dostaneme počet segmentů v kombinaci pro každou jednu frázi.
Výsledek může vypadat podobně:

Tím máme práci v Open Refine hotovou a jdeme na excel, kde pomocí kontingenčních tabulek dostaneme požadované výsledky.
Porovnání hledaností kombinací podle počtu segmentů
Prvním výstupem je porovnání hledaností jednotlivých kombinací podle počtu segmentů. Zní to složitě, ale v podstatě tím chci jen ukázat, kolik kombinací segmentů se vyplatí řešit.
Uvedu příklad na všech datech v klíčovce (tedy bez výběru konkrétního typu sortimentu).

Co nám vlastně tento obrázek říká? V zásadě to, že rozhodně musíme pokrýt kombinace jednoho segmentu. Jenže to je většinou jen hlavní kategorie, například trička, mikiny, kalhoty, tepláky atp. Tam je to zcela jasné.
Musíme ale pokrýt i kombinace dvou segmentů. To už jsou fráze stylu “červená trička”, “mikina XXL”, atp. Tam je i největší hledanost ze všech kombinací. Takže by měly být pro nás nejdůležitější.
Pokud nechceme zahodit nějakých 400 tisíc lidí měsíčně, kteří hledají i fráze spadající do kombinací tří segmentů, pak se na ně musíme zaměřit taky. Může jít o fráze typu “červené tričko Nike”, “pánské košile s límečkem”, atp.
Zda se zaměřit i na fráze spadající do kombinace čtyř segmentů už je otázkou. Stále jde o nějakých cca 28 tisíc hledání měsíčně. U kombinace čtyř segmentů jde o fráze podobného ražení: “pánské červené čepice Nike”, “dámské trička s dlouhým rukávem a velikostí L” atp.
Porovnání hledanosti u kombinací hlavních segmentů
Druhým výstupem je porovnání kombinací hlavních segmentů (v podstatě názvů sloupců z klasifikační analýzy). Nejdříve si ale musíme data zpracovat v excelu pomocí kontingenční tabulky.

Do řádků vložíme kombinace hlavních segmentů a počet segmentů v kombinaci.
Do hodnot pak hledanost.
A do Filtrů Hlavní kategorie. To abychom si mohli zobrazit kombinace pro různé typy sortimentu (trička, mikiny atp.).
Příklad:

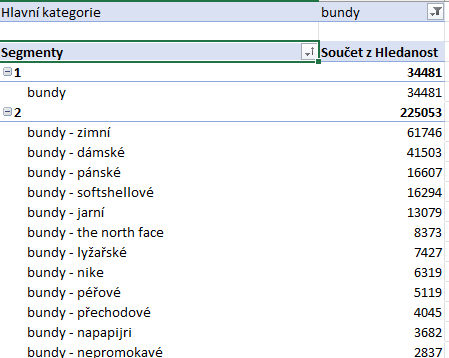
V tomto příkladě jsem si z filtru nahoře vybral jen “bundy”.
U kombinace dvou segmentů jsou výrazně více hledané kombinace “Hlavní kategorie – období” (zeleně) a “Hlavní kategorie – pro koho” (modře). Znamená to, že bychom se měli zaměřit např. na tvorbu vstupních stránek právě pro ně a začít je tvořit prioritně. Zastávají fráze typu “zimní bundy” nebo “pánské bundy”.
Jenomže se nyní podívejme do kombinace tří segmentů, zejména pak tu červeně označenou. Když porovnáme hledanost, tak tato kombinace tří segmentů o nějakých 13 tisíc převyšuje měsíční hledanost kombinace dvou segmentů (modře).
Tím se nám mění priority!
Ze všeho nejdříve bychom tak měli začít ladit kombinace zeleně, pak červeně a až potom modře orámované.
A tak můžeme pokračovat dále.
V podstatě jsme si tímto postupem zobrazili priority pro tvorbu vstupních stránek jednotlivých kombinací. A to pro každou hlavní kategorii zvlášť, protože si ji nahoře můžeme měnit a tím pádem se nám budou měnit i kombinace segmentů.
Dalším možným využitím takto zobrazených dat je možnost seřazení filtrů podle hledaností. Vezměme si příklad, kdy máme filtry na eshopu zobrazeny v levém sloupci. Podle čeho zvolíme, který filtr dát výš a který níž? Nemělo by jejich pořadí odpovídat jejich hledanosti?
Proto z výše uvedeného obrázku můžeme vyčíst, že jako první by měl být v případě zvolené kategorie “bundy” filtr pro výběr „období“, pak pro „pro koho“, následovat by měla „značka“, „materiál“ atd.
Porovnání kombinací hodnot segmentů
Abychom se mohli dále podívat, které konkrétní hodnoty segmentů spadají do jednotlivých kombinací, tak si je pomocí kontingenční tabulky zobrazíme podobně jako předchozí tabulku:
Podle této tabulky například můžeme nastavovat pořadí jednotlivých hodnot ve filtrech tak, aby byly nahoře vždy ty nejhledanější. Většinou je řazení nastaveno náhodně, nebo nějak ručně na základě odhadů. Tady podle této tabulky jsme schopni vložit do horních pozic nejhledanější hodnoty.
Pokrytí jednotlivých kombinací segmentů ve vyhledávačích
Třetím výstupem může být zobrazení pokrytí jednotlivých kombinací segmentů ve vyhledávačích Google nebo Seznam. Můžeme tak relativně jednoduše podchytit, které kombinace máme na eshopu špatně pokryté.
Procento pokrytí vyjadřuje počet frází, které se zobrazují ve vyhledávači Google do 60+ pozice.
Když se opět vrátím ke klasickému výstupu z analýzy klíčových slov, tak tam jsme se vždy dozvěděli jen to, která kategorie nebo kategorie s vybraným parametrem, má jaké pokrytí ve vyhledávačích. Zjistili jsme ale vždy jen jednu URL. A nebo maximálně pokrytí jednoho parametru.
Tady si ale můžeme zobrazit, jak kvalitně jsou pokryty různé kombinace parametrů.
Opět příklad:
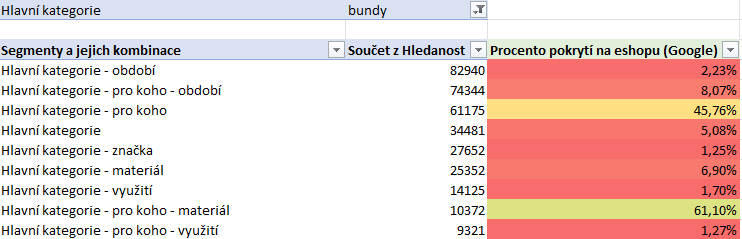
Co tabulka zobrazuje?
Každá jedna kombinace segmentů (v tomto případě každý jeden řádek) zastupuje nějakou sadu frází, které pod ní spadají. Z tabulky výše tak lze vyčíst, že fráze spadající pod kombinaci “Hlavní kategorie – pro koho” a “Hlavní kategorie – pro koho – materiál” jsou pokryté docela solidně.
Naopak fráze spadající pod kombinaci “Hlavní kategorie – období” jen z 2,23%.
Úplně stejně bychom mohli zobrazit například i procenta pokrytí podle počtu segmentů ve vyhledávači Google i Seznam. Ale to už si vyzkoušejte sami, dejte si to za domácí úkol 🙂
Co jsme tím vším vlastně získali?
Tak především jsme díky tomu schopni prioritizovat kombinace filtrů. Jsme schopni určit, kterým kombinacím věnovat pozornost větší, kterým třeba vůbec. Které kombinace vůbec vytvářet a které už ne. Do jaké hloubky musíme jít.
Z praxe vím, že kombinatorika jednotlivých filtrů je docela složitá záležitost. Co ještě pouštět do indexace a co už ne? Kterým kombinacím mít možnost nastavit všechny OnPage prvky? A kolik nám vlastně utíká potenciálu návštěvnosti tím, že některé kombinace nemáme ve vyhledávačích pokryty?
To jsou všechno otázky, na které jsme schopni výše popsaným zpracováním dat najít odpovědi.
To nám může ušetřit spoustu peněz i času. A o to jde. Efektivita především 🙂